Update June 16: Please see Questions and Answers below for answers to questions posed by participants.
Congratulations to our winners:
The 2015 MEMOCODE Design Contest is sponsored by Microsoft and Xilinx. We thank both sponsors for their support.
The skyline query operation [1] (also called the "maximum vector problem") is used to identify potentially interesting or useful data points in large multi-dimensional datasets. When the dataset changes over time (through addition and subtraction of points), this is called the "continuous skyline" query [2]. The 2015 MEMOCODE Design Contest problem is to implement a system to efficiently compute the continuous skyline of a large dynamic dataset.
Below you will find descriptions of: the problem, example datasets, and a functional reference implementation. For instructions to download the code and datasets, please sign up by e-mailing Peter Milder at peter.milder@stonybrook.edu with your team information.
Participants will have one month to develop systems to solve this problem. A $1000 prize will be awarded to each of two winning teams: the team with the best absolute performance and the team with the best cost-adjusted performance. Each team delivering a complete and working solution will be invited to prepare a 2-page abstract to be published in the proceedings and to present it during a dedicated poster session at the conference. The winning teams will be invited to contribute a 4-page short paper for presentation in the conference program.
The contest is open to industry and academic participation. A team may include both industry and academic members. There is no limit on the number of members of a team, or the number of teams per institution. However, each person may participate in only one team.
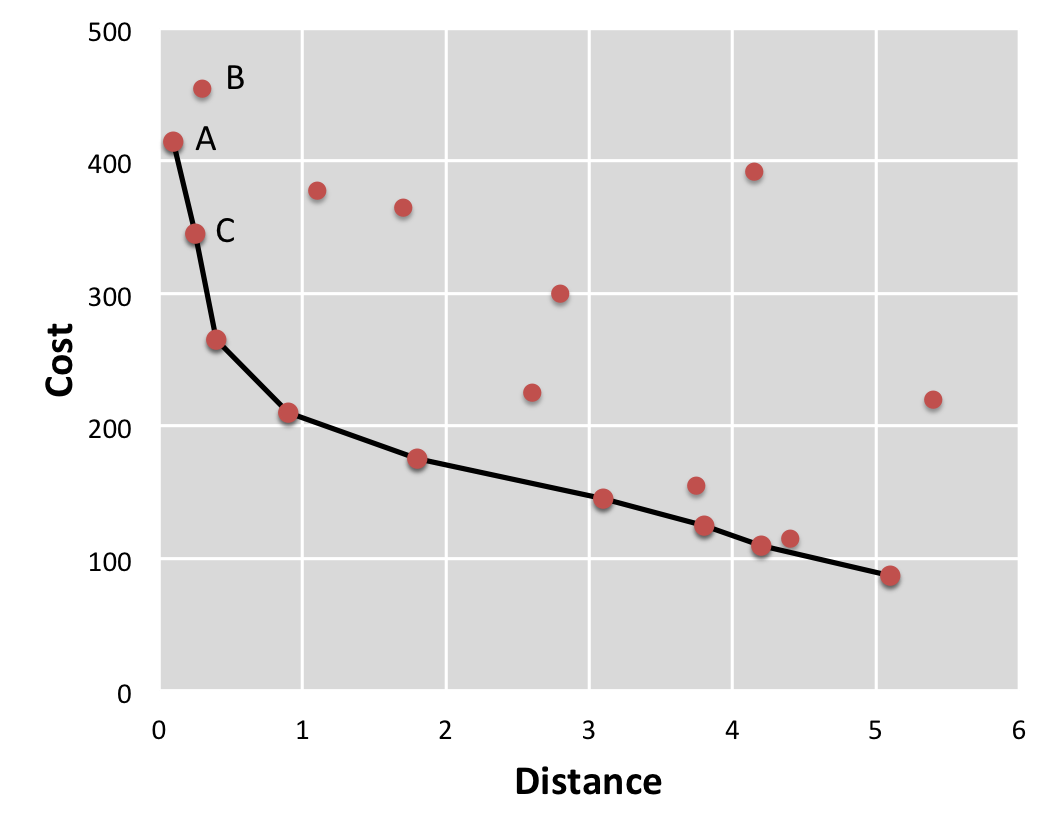
A common example to illustrate the idea behind the skyline operation is to consider the choice of a vacation hotel (as in [1]). Imagine you are choosing a hotel for vacation on a tropical island, and you are concerned only with each hotel's cost and its distance to the beach. We can visualize your options in the following figure.
If we consider only these two metrics (cost and distance) we can easily identify the hotels that you may want to consider. For example, we see that the hotel labeled "A" is both closer to the beach and less expensive than hotel "B". This means that A dominates B. When we compare A and C, we see that A is better in one metric (distance) while C is better than A in the other (cost). For this reason, neither A nor C dominate each other. The skyline is the set of points which are not dominated by any other. The figure illustrates these points by connecting them with a solid line.
In this example, the dataset only contains two dimensions (cost and distance). If a vacationer cares about other aspects of the hotel (e.g., the hotel's quality), then more dimensions must be added to the dataset. We will use \(m\) to represent the number of dimensions in a dataset.
To present the problem more completely:
Definition: Let \(D\) represent a dataset of \(n\) elements \(d_0, \dots,, d_{n-1}\), each with \(m\) dimensions. The skyline of \(D\) is the set of all of its elements which are not dominated by any element of the set.
Definition: Element \(d_a\) dominates element \(d_b\) if and only if \(d_a\) is better than \(d_b\) in at least one dimension, and better than or equal to \(d_b\) in all \(m\) dimensions. We will say that a number \(x\) is "better" than another number \(y\) if and only if \( x < y\).
Our previous example assumed that the dataset was constant. However, large complex datasets are often dynamic in nature. The continuous (or "continuous time-interval") skyline computation [2] is performed on a dataset where entries are added or removed over time.
A naive approach to this can simply re-calculate the entire skyline each time an element is added or removed. However, this can be quite inefficient; if only a portion of the active dataset has changed since the last computation, many of the necessary comparisons have already been performed.
We will model time as a series of discrete timesteps, and we will encode the dataset's changes with an activation time \(a\) and a deactivation time \(v\) for each of the \(n\) entries in the input set.
At time-step \(t\), our goal is to find the skyline among all entries in \(D\) that have activation time \(a \leq t\) and deactivation time \(v > t\). The output of our system will be the indices (in \(D\)) of the skyline elements, and the number of skyline entries found per time-step.
Your system will take as input:
The dataset is sorted by activation time (that is, \(D\) is ordered from earliest to latest activation time).
For each timestep \(t = 0,1,\dots, T\), your system must find the skyline across all data elements valid at timestep \(t\). Your system will store their indices (relative to their location in \(D \)) in memory, as well as the number of valid skyline points found. The maximum time-step \(T\) is the largest deactivation time in the dataset; your system may assume \(T\) is given.
The timed portion of your solution must start with all input data in main system memory, and it must conclude with all output data in main memory.
Elements in \(D\) are given as unsigned integers. The range of the input values is limited such that every input element can be represented as a 16-bit unsigned value.
The final output values are the indices of the skyline entries of \(D\) at each timestep (thus, unsigned integers between \(0\) and \(n-1\)).
Designers may choose to optimize the datatype as appropriate. A solution will be considered to be correct if all skyline indices match. There is no constraint on the order that the indices are produced in a given time.
We are providing a reference software implementation to serve as the functional reference for the contestants' optimized implementations. The reference implementation reads input files for the dataset \(D\), and the vectors which give the activation and deactivation time for each element. For each time step, it then finds the skyline, records the number of skyline entries found, and stores the resulting indices of the skyline elements.
Based on the problem definition, the order of the output values does not matter. For convenience, the functional reference sorts them; this will allow an easy use of diff to determine if two output files are equivalent. This sorting does not need to be in your implementation (and its runtime can be ignored).
Lastly, a Makefile is provided; typing “make runsmall” at the command line will compile the software, run it on a small example dataset, and verify the correctness of the results. For more information on the reference software and its inputs and outputs, please see readme.txt included with the software.
Three datasets are provided to aid in validation and development. Each set contains an \(m\)-dimensional input dataset \(D\), and the vectors which give the activation and deactivation time for each element. Each set is accompanied by a reference solution that provides the sorted indices of the skyline elements.
The three datasets provided are named small, medium, and large. More information about the dataset input and output file names and instructions are included in readme.txt. Typing “make runsmall” at the command line will compile the reference design, run it on the small example dataset, and verify correctness of the results.
Contestants have one month to implement the system using their choice of platforms such as FPGAs, CPUs, GPGPUs, etc. The system must be validated using the supplied reference inputs and outputs discussed above.
(This paragraph updated to clarify details of the evaluation dataset on June 16, 2015. Please see Questions and Answers below.) Contest winners will be selected based on the performance of their systems. Performance will be measured using a dataset that has the same size \(n\) and dimensions \(m\) as the "large" dataset. We will also guarantee that the number of timesteps and the maximum number of skyline elements per timestep will be the same or smaller than in the large dataset. The time taken to initialize data and read out the results is excluded from the run time measurement. (See also the comments in reference software's main function.)
As in previous design contests, winners will be chosen in two categories. First, the “pure-performance” award will be based only on the fastest runtime. Second, the “cost-adjusted-performance” award will be chosen by multiplying runtime by cost of the system. For example, a $100 system with runtime of 60 seconds is equivalent to $200 system with runtime of 30 seconds. The cost of the system is based on the lowest listed prices (academic or retail). If no price is available (e.g., using an experimental platform), judges will estimate the system cost. Contestants are requested to submit cost estimates of their systems to aid in judging.
The winning groups (for best performance and best cost-adjusted-performance) will each be awarded a $1000 prize.
For instructions to download the code and datasets, please sign up by e-mailing Peter Milder at peter.milder@stonybrook.edu with your team information.
Before 11:59PM US Eastern Time on July 1, 2015, submit your design solution in a tar or zip file to peter.milder@stonybrook.edu
After your submission you will receive a confirmation email within 24 hours. If you do not receive this information email after 24 hours, please contact peter.milder@stonybrook.edu
Your submission should contain the following items in a single zip or tar file:
Documentation in the form of PowerPoint slides is perfectly acceptable. The quality and conciseness of the documentation will help in judging. The judges will make a best effort to treat the design source files as confidential. The information in other items is considered public.
If you have any questions, please contact Peter Milder.
May we pre-process the dataset?
No. The timestamps represents a scenario where your database receives a series of dynamic data updates over time. So any pre-processing you do on this data must be done within the timed portion of your design.
Which dataset will be used to evaluate the runtime of the design? What can we assume about it?
The final evaluation will be performed on a new dataset that has the same size \(n\) and dimensions \(m\) as the "large" dataset. We will also guarantee that the number of timesteps and the maximum number of skyline elements per timestep will be the same or smaller than in the large dataset.
Can we compute the skylines for different timesteps in parallel or overlapped (as opposed to serially computing them one at a time)?
Yes.
[1] Börzsöny, S., Kossmann, D., & Stocker, K. The Skyline operator. Proceedings 17th International Conference on Data Engineering, 2001.
[2] Morse, M., Patel, J. M., & Grosky, W. I. Efficient continuous skyline computation. Information Sciences, 177(17), 3411–3437, 2007.
Peter Milder, peter.milder@stonybrook.edu
This page uses MathJax for displaying mathematical formulas. If your browser has Javascript disabled, formulas will not display correctly.
Previously: 2014 MEMOCODE Design Contest.